

I’ve got the requirement to generate different project specific documents based on Microsoft Word templates, with input data from an external system. These documents should be generated and stored in the relevant SharePoint site, preferably with (only) one Power Automate flow that populates a dynamic set of Microsoft Word templates.
Joe Unwin wrote the blog post ‘A Complete Guide to Creating and Populating Word Templates with Power Automate’ where he explains how to handle the dynamic file schema when the file input for the template is based on dynamic content, but with the following disclaimer:
This will NOT work for documents that are generated as a template as the ID’s will continue to change, To handle this you will need to open the XML document on Power Automate and create a flow that extracts the ID based on the alias.
So I guess my name is Neo and I’m the one to create the flow to save the world community your day.
The challenge is to look for the value of the tag element in the XML document that matches the name of an attribute from the input data, and combine the related id value from the XML document with the value of the attribute from the input data. Resulting in the dynamic file schema as input for the ‘Populate a Microsoft Word template’ action.

FYI: The raw input data is XML from a SOAP web service and it’s converted to json, so the attributes from the XML are turned into keys with a ‘@’ as prefix. This is specific for my use case. And I use the tag element instead of the alias element to look for a match in the XML document. Beware that the tag value and key name must be equal to have a match, so make sure that both are configured properly.
Since I have to navigate the XML document I want to make use of the elegant ‘xpath’ function instead of dirty string manipulation. I’ve been watching some videos of Damien Bird to get the inspiration for finding the path to the solution of this challenge. This is the overview of the flow:



The essential steps of the flow are:
- Get the input data (includes the name of the requested Microsoft Word templates)
- Get all the Microsoft Word templates from a location in SharePoint
- Apply to each input row
- Filter the requested Microsoft Word template from the output of the previous action
- Extract the specific Microsoft Word template and get the document.xml file
- Extract the id values based on the tag that matches the name of the attribute from the input data
- Combine the id values with the values of the matching attributes from the input data
- Populate the Microsoft Word template with the dynamic file schema
- Create a file in SharePoint with the content of the previous action
- Delete the folder with the archive file and extracted files
The ‘Apply to each’ is based on the output of the ‘Compose | Rows’ action with the input data, that includes the name of the template (blueprint) used in the ‘Filter array’ action.
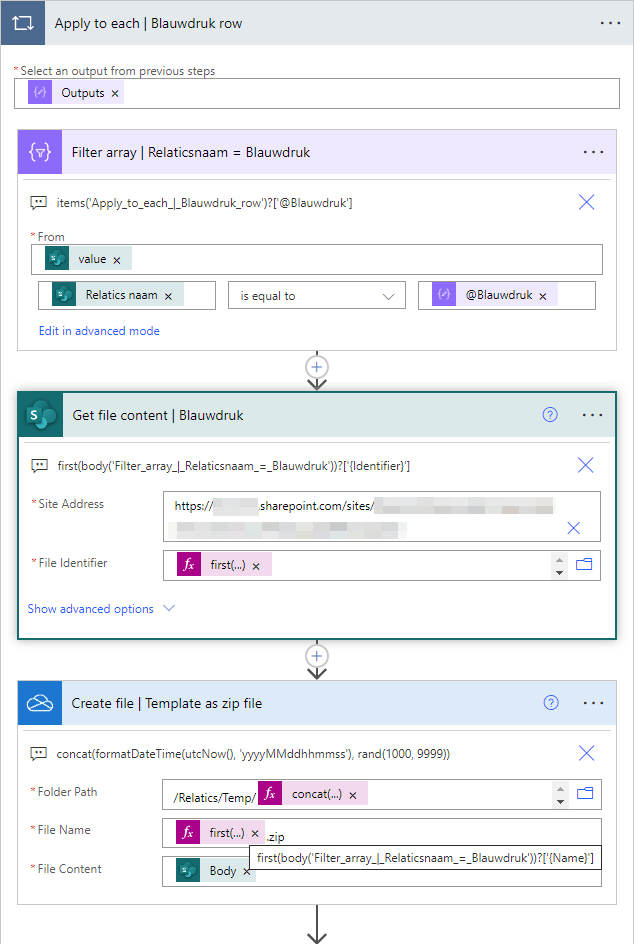
To be able to extract the Word template I create a .zip file (from its content) in a temporary folder in OneDrive for Business with the expression for the ‘Folder Path’:
concat(formatDateTime(utcNow(), 'yyyyMMddhhmmss'), rand(1000, 9999))The ‘Extract archive to folder’ action uses ‘Path’ without extension as input for the ‘Destination Folder Path’:
substring(outputs('Create_file_|_Template_as_zip_file')?['body/Path'], 0, sub(length(outputs('Create_file_|_Template_as_zip_file')?['body/Path']), 4))The content of the ‘document.xml’ file contains the XML that is used in the subsequent actions.

I’ve tried to iterate over the tag elements in the XML document, but since they are not part of a hierarchical structure it doesn’t work. Therefore I’ve created a simplified XML structure for both the tag and id elements.
The ‘xpath’ function can’t process XML with the ‘:’ character in the elements and attributes, so it’s replaced by a ‘_’ in the ‘Select’ actions with respectively the following expressions for the tag and related id elements:
xpath(xml(replace(outputs('Get_file_content_|_document.xml')?['body'],'w:','w_')),'//w_tag[@w_val]')xpath(xml(replace(outputs('Get_file_content_|_document.xml')?['body'],'w:','w_')),'//w_tag[@w_val]/following-sibling::w_id')
In the ‘Compose’ actions the XML structure is completed with a root element:
<root>@{join(body('Select_|_XML_tag'),'')}</root>Now we have the correct starting position for the real magic. To construct the dynamic file schema only 2 actions are needed (Select, Compose), but to show off a bit I add a ‘Filter array’ action as a starter to keep the dynamic file schema clean from null values (in case of no match) and empty strings (from the input data).
The input for the ‘Filter array’ action is a range starting with 1 (first index number in xpath) and as count the number of tag elements in the XML document based on the count function in xpath:
range(1, int(xpath(xml(replace(outputs('Get_file_content_|_document.xml')?['body'], 'w:', 'w_')), 'count(//w_tag[@w_val])')))The item() is the index number to iterate over the tag elements and get the value to set the name of the key from the input data. Null values and empty strings are filtered out by using the not(empty()) function: (remove the yellow marked part if your key names don’t start with ‘@’)
@not(empty(items('Apply_to_each_|_Blauwdruk_row')?[concat('@', xpath(xml(outputs('Compose_|_Join_XML_tag')), concat('string(//w_tag[', item(), ']/@w_val/.)')))]))The input for the ‘Select’ action is a range of (index) numbers to iterate over the id elements in the XML and get its value to set the keys in the mapping:
xpath(xml(outputs('Compose_|_Join_XML_id')), concat('string(//w_id[', item(), ']/@w_val/.)'))Next is to iterate over the tag elements in the XML and use its value to set the name of the key from the input data and get its value to set the (key) values in the mapping: (remove the yellow marked part if your key names don’t start with ‘@’)
items('Apply_to_each_|_Blauwdruk_row')?[concat('@', xpath(xml(outputs('Compose_|_Join_XML_tag')), concat('string(//w_tag[', item(), ']/@w_val/.)')))]In the ‘Compose’ action the output is converted to proper JSON to meet the (dynamic file) schema with the expression:
json(replace(join(body('Select_|_Filtered_dynamicFileSchema'),','),'},{',','))The dynamic file schema is now ready to be used as input for the ‘Populate a Microsoft Word template’ action.
The input for ‘File’ is based on the expression:
substring(first(body('Filter_array_|_Relaticsnaam_=_Blauwdruk'))?['{FullPath}'],indexOf(first(body('Filter_array_|_Relaticsnaam_=_Blauwdruk'))?['{FullPath}'],'/'))The ‘Location’ and ‘Document Library’ could/should be set by environment variables of the type Data Source and Text respectively. See this blog post for more info.

The output of the previous action is used to create a file in SharePoint, where the ‘Site Address’ is based on the project number from the input data and the ‘Folder Path’ is specified in the metadata of the selected Word template.

The last action is to delete the temporary folder with the archive file and extracted files by sending an HTTP request to SharePoint. The Server Relative URL is a combination of the path of the Documents library in OneDrive for Business and the output of the expression:
substring(outputs('Create_file_|_Template_as_zip_file')?['body/Path'],0,lastIndexOf(outputs('Create_file_|_Template_as_zip_file')?['body/Path'],'/'))When the flow is run the dynamic file schema is built dynamically and used to populate the Microsoft Word template.

In this way it’s possible to populate a dynamic set of Microsoft Word templates in Power Automate flow.
On your step ‘Populate a Microsoft Word Template’, did you find a way to make the ‘Document Library’ dynamic?
In your screenshots, you have selected DOCUMENTEN.
But if you export the flow to a different environment which uses a different SharePoint site, that parameter will fail and you will need to select the corresponding DOCUMENTEN again.
Any ways on how to overcome this?
Hi Shidin,
You could use an environment variable of the type Text for that. See this blog post for more info.
Thanks for sharing your flow! I appreciate the detailed explanation of each step and how you handle the dynamic file schema. Using XPath instead of string manipulation is a more elegant solution. I’ll definitely be referencing Damien Bird’s videos as well. Keep up the great work!
hi StefanS365,
This is what exactly I was looking for.
Just a small request if you could share the workflow as ZIP or JSON would really help.
Thanks,
Cheers,
Hasan
Hi,
Thanks for the this blog, much appreciated the work you have done, can u please expand your compose row action as well? how you are composing rows for input data ? are these values for placeholders coming from share point list?
moreover what
Hi Zami,
The outputs of the Compose Rows action is an array of one or more JSON objects. See the screenshot of the Input data in the top image. In my case the input data is coming from an external system, but that can be any system, list or table. As long as the JSON object contains the attribute names to match the tag values and then combine the id values with the attribute values.
The name or URL of the Word template can be included in the input data or from another action outputs.
Can u please explain compose rows here?
Thanku
Hi Muzammil,
See my comment above.
This saved my world community